主成分分析と因子分析
主成分分析、因子分析を解説する。因子分析には探索的因子分析と確認的因子分析がある。
主成分分析
princomp( ) 関数で回転しない主成分分析を行える。prcompはサンプルサイズ < 変数の数のときに使うらしい。
参考リンクト
- Rで主成分分析
- Rで主成分分析2
- Rjpwiki: 統計手法の実地への適用限界 "要するに,二つある関数のうち,princomp は忘れて,いつも prcomp を使えばよいと言うだけのことである" らしい
- 金先生のRと主成分分析。prcomp関数の解説。
- S-PLUSのFAQ。princompがお奨めだそうだ。
- シリウス先生の心理統計学: 主成分分析モデルの応用。"prcomp()は計算時に不偏分散を用いるのに対して、princomp()では標本分散を用いている。両者に若干の違いはあるが、基本的にはどちらを使っても構わない" だそうだ。
- gregmiscパッケージのfast.prcompという関数もあるらしい (Rjpwikiのオブジェクト一覧) 。
- 神谷先生: R コマンダーによる主成分分析
# ローデータを指定し、cor=Tとすると標準化してから主成分が抽出される。
dat <- USArrests
fit <- princomp(dat, cor=TRUE)
summary(fit) # 説明された分散
loadings(fit) # 主成分負荷量
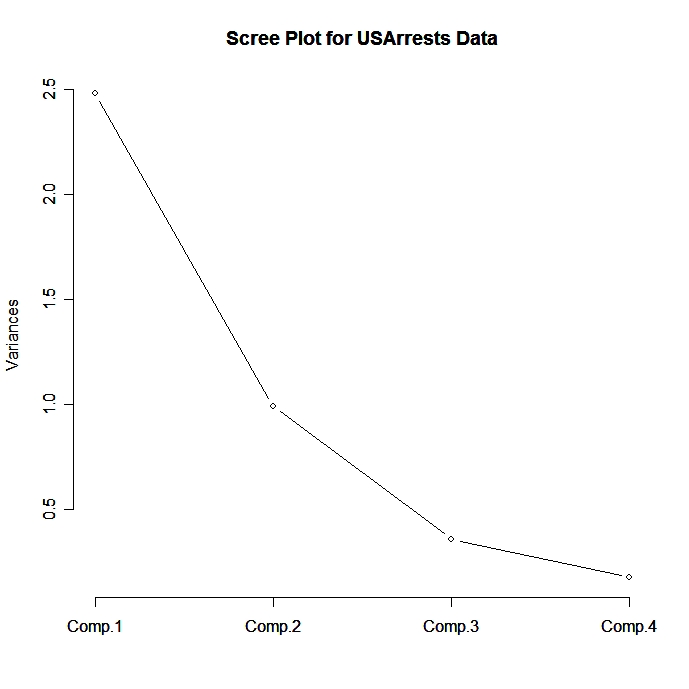
plot(fit,type="lines") # スクリープロット
fit$scores # 主成分得点
win.graph()
biplot(fit)
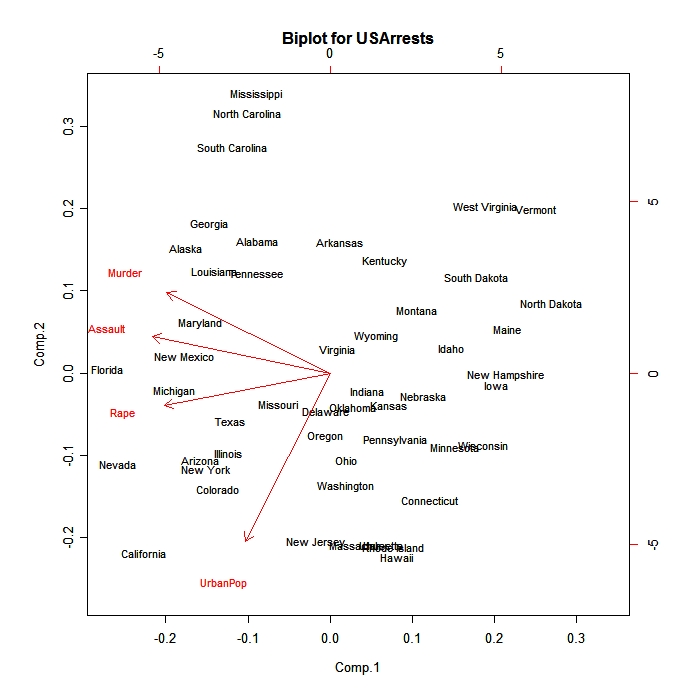 click to view
click to view
cor=FALSE とすると共分散行列に基づいた主成分を抽出する。covmat=は相関行列または共分散行列を直接データとして投入するかどうか。もし相関 or 共分散行列を投入した場合 n.obs=. でサンプルサイズを指定する。
psych パッケージの principal( ) 関数でも主成分分析が行える。
# バリマックス回転の主成分分析。4つの主成分を抽出する。
library(psych)
dat <- USArrests
fit <- principal(dat, nfactors=4, rotate=TRUE)
fit # 結果
データにはローデータか共分散行列を指定できる。欠損値はペアワイズ除去される。rotate=TRUE とした場合、バリマックス回転が行われる。
# 足立浩平 (2006). 多変量データ解析法――心理・教育・社会系のための入門―― ナカニシヤ出版の例より
# 表 3.1 p24
ppt <- c(88,52,77,35,60,97,48,66,78)
wrt <- c(70,78,87,40,43,95,62,66,50)
int <- c(65,88,89,43,40,91,83,65,48)
dat <- data.frame(ppt, wrt, int)
mean(dat)
sapply(dat, var)
fit <- princomp(~ppt+wrt+int, cor=F, data=dat) # 相関行列をもとにした分析をするにはcor=Tとする
fit2 <- prcomp(dat, cor=F)
# 主成分得点 表3.1 p22
# 単にprincomp(dat) でも同じ
fit$scores
fit2$x
# 各主成分の係数 表3.5 p32
loadings(fit)
unclass(loadings(fit)) # 行列にしただけ
fit2$rotation
# 固有ベクトルなので以下と同じ
eigen(cov(dat))$vectors
# 各主成分得点どうしの共分散 表3.6 p32
cov(fit$scores)
round(cov(fit$scores),1) # みやすく四捨五入
round(cov(fit2$x),1)
# 成分行列 (いわゆる負荷量)
t(fit$sd * t(fit$loadings ) )[, drop = FALSE]
t(fit2$sdev * t(fit2$rotation ) )[, drop = FALSE]
# 結果が異なる。おそらくprcompは Unlike princomp, variances are computed with the usual divisor N - 1. であるため、標準偏差の値が異なる
fit$sd
fit2$sdev
sqrt(fit2$sdev^2 *(8/9)) # 不偏分散を標本に戻すと一致
# 説明率、累積説明率 図3.6 p27
summary(fit)
print(summary(fit2), digits=10) #
基本的には同じ結果だが、prcompのsummaryは小数点第5桁までで区切っているのがわかる
# 固有値
fit$sd^2
fit2$sdev^2
# 固有値なので以下と同じ
eigen(cov(dat))$value
# psychパッケージで
fit3 <- principal(dat, nfactors=3, rotate=F, scores=T)# psychパッケージでは標準化した相関行列がデフォルトで用いられる。回転もデフォルトだとバリマックス回転が行われる。
print(fit3, digits=5) # psychパッケージのprincipal関数
fit3$scores # psychパッケージでは標準化した主成分得点が算出される
小塩先生のサイト 心理データ解析 補足説明(1) より
SPSSの結果と一致する
gai <- c(3, 6, 6, 6, 5, 4, 6, 5, 6, 6, 5, 5, 6, 5, 5, 6, 4, 6, 5, 4)
sha <- c(4, 6, 5, 7, 7, 5, 6, 5, 6, 5, 4, 5, 6, 5, 6, 6, 4, 6, 3, 6)
sek <- c(4, 7, 7, 5, 6, 5, 7, 4, 6, 6, 4, 6, 5, 4, 4, 6, 3, 7, 4, 6)
chi <- c(5, 8, 5, 4, 5, 5, 6, 5, 7, 6, 5, 5, 5, 4, 5, 4, 6, 4, 3, 3)
sin <- c(4, 7, 5, 6, 5, 6, 4, 5, 7, 5, 5, 4, 6, 5, 6, 4, 5, 5, 5, 5)
sun <- c(4, 7, 6, 5, 5, 6, 4, 6, 6, 5, 5, 5, 5, 3, 6, 5, 6, 5, 4, 4)
dat <- data.frame(gai, sha, sek, chi, sin, sun)
library(psych)
fit <- principal(dat, nfactors=2, rotate=F, scores=T)
print(fit, digits=5)
fit$scores
探索的因子分析 (exploratory factor analysis)
factanal( ) 関数で最尤法による因子分析が行える。かつては主因子法・バリマックス解がデフォだったが、現代では最尤法・斜交解をやるもんらしい。
参考リンク
- Rで最尤解の因子分析
- Rで主因子解の因子分析
- Rで因子分析
- DiStefano,, C., Zhu, M., & Mindrila, D. (2009). Understanding and using factor scores: Considerations for the applied researcher. Practical Assessment, Research & Evaluation, 14, Available online: http://pareonline.net/getvn.asp?v=14&n=20 .
# 3因子解・プロマックス回転 共分散行列をデータに用いる
dat <- Harman74.cor$cov
fit <- factanal(covmat=dat, n.obs=145,factors=3, rotation="varimax")
print(fit, digits=2, cutoff=.3, sort=TRUE)
load <- fit$loadings
plot(load,type="n", main="Harman74 Data")
text(load,labels=rownames(dat),cex=.7)
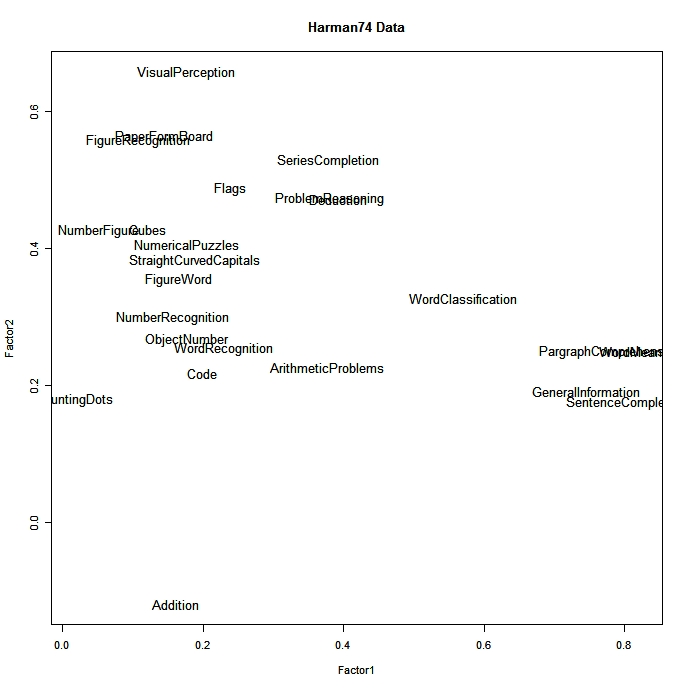 click to view
click to view
The rotation= は "varimax", "promax", and "none" が選択可能。 scores="regression" or "Bartlett" で因子得点を算出 (たぶん回帰法が普通。参考として、DiStefano et al., 2009。) 。covmat= は相関行列か共分散行列を直接データとして与えるときに使用。 この場合、 n.obs=. でサンプルサイズを指定する。
psych パッケージの fa( ) 関数でいろんな因子分析ができる。以下使い方の覚書
# 固有値とスクリープロット
library(psych)
faev <- fa.parallel(dat)
faev
# 因子推定
# 最尤法
factMLres <- fa(r=dat3, nfactors=3 ,rotate="promax", fm="ml", scores=T)
# 主因子法
factPAres <- fa(r=dat3, nfactors=3 ,rotate="promax", fm="pa", scores=T)
# 一般化最小二乗法
factGLSres <- fa(r=dat3, nfactors=3 ,rotate="promax", fm="gls", scores=T)
# 重みつき最小二乗法
factWLSres <- fa(r=dat3, nfactors=3 ,rotate="promax", fm="wls", scores=T)
# 最小残差法 (重みづけない最小二乗法)
factOLSres <- fa(r=dat3, nfactors=3 ,rotate="promax", fm="minres", scores=T)
# 結果の出力
print(factMLres, cut=0, sort=T, digits=5)
# 回転 (rotate="") のオプション
# 回転なし。いわゆる初期解ってやつ
"none"
# 直交解
"varimax", "quartimax", "bentlerT", and "geominT"
# 斜交解
"promax", "oblimin", "simplimax", "bentlerQ, and "geominQ" or "cluster"
因子得点はscores=T。推定は (たぶん) 回帰法
library(psych)
? fa
のDetailも勉強になる
因子数の決定
nFactors パッケージが因子数の決定に便利。いわゆるスクリープロットを描いてくれる。詳細はRaiche, Riopel, and Blaisの PowerPoint presentation 参照 (オリジナルURL: http://www.er.uqam.ca/nobel/r17165/RECHERCHE/COMMUNICATIONS/2006/IMPS/IMPS_2006.ppt#1) 。もちろん解釈可能性が大事。また、psychパッケージのfa.parallel関数も有用。
参考リンク
- Revelle, W. (2007). Determining the number of factors: The example of the NEO-PI-R. Available online: http://www.personality-project.org/R/book/numberoffactors.pdf
- 堀 啓造 (2005). 因子分析における因子数決定法――平行分析を中心にして―― 香川大学経済論叢, 77, 35-70.
library(nFactors)
ev <- eigen(cor(dat)) # get eigenvalues
ap <- parallel(subject=nrow(mydata),var=ncol(mydata),
rep=100,cent=.05)
nS <- nScree(ev$values, ap$eigen$qevpea)
plotnScree(nS)
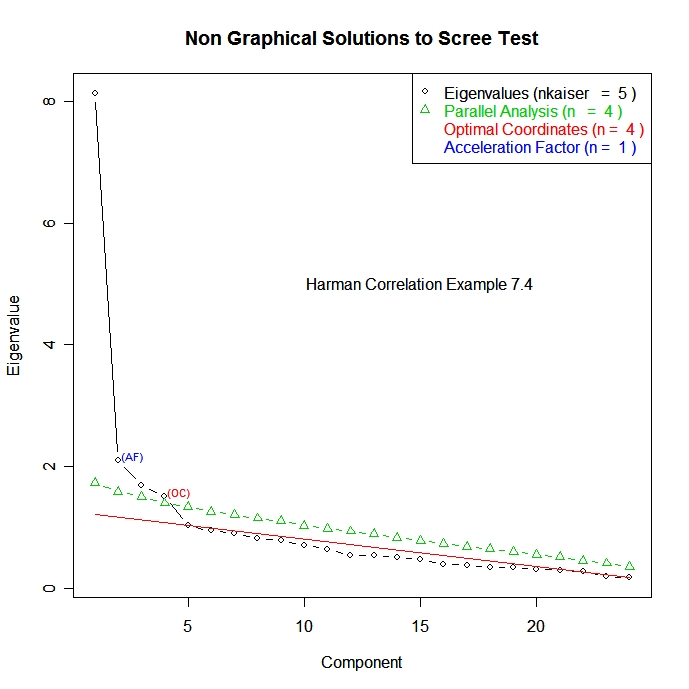 click to view
click to view
Going Further
FactoMineR パッケージは探索的因子分析に関する様々な関数がある。
参考ページ
また、GPARotation パッケージを使うとvarimax, promax以外に様々な回転が行える。
...と、Quick-Rではいっているが、psychパッケージのfa関数でやるのが一番いいと思う。
分析例1
# データ
# 足立浩平 (2006). 多変量データ解析法――心理・教育・社会系のための入門―― ナカニシヤ出版
# 第11章 探索的因子分析 (その1) p105-113
# 表8-1
dat <- read.delim("data_Adach2006.8-1.dat")
head(dat)
# 因子分析の手順 (図11.4 (A) p111)
# 1.因子数の選定
# 2. 解の1つを求める
# 3. 回転
# 1. 因子数の選定
# 因子数は理論から決める
# psychパッケージのfa.parallelは平行分析による因子数を提案してくれる。
library(psych)
fa.parallel(dat))
# Parallel analysis suggests that the number of factors = 2 and the number of components = 2
# 因子数は2、主成分数は3
# 2. 解のひとつを求める
# 初期解を求める
fit <- fa(r=dat, nfactors=2 ,rotate="", fm="ml", scores=T)
print(fit, digits=5)
# 3. 回転
# プロマックス回転
fit.ml.promax <- fa(r=dat, nfactors=2 ,rotate="promax", fm="ml", scores=T)
print(fit.ml.promax, digits=5)
構造方程式モデリング
確認的因子分析 (Confirmatory Factor Analysis: CFA) は構造方程式モデリング (Structural Equation Modeling: SEM) の1種で、Rではsem パッケージで行える。ただし、構造方程式モデリングが重要ならAMOSの購入を勧める。
適合度指標
一般に、カイ二乗値、GFI、AGFI、RMSEA、CFI、AIC,CAIC、BIC などが使われる。(たぶん)まずはRMSEA、それからCFI。で、AICでほかのモデルと比較する。カイ二乗値、GFI系はいろいろよくないらしいが、慣習として (?) 報告だけはしておく。
- カイ二乗値:小さくて、有意じゃないとよい。75から200ケースくらいならよいが、それ以上になると常に有意になってしまうのでよろしくない指標。
- GFI: Goodness of Fit Index 。0から1までの値で、大きいほどよい。サンプルサイズに依存するのでおすすめしない。
- AGFI: Adjusted Goodness of Fit Index。0から1までの値で、大きいほどよい。サンプルサイズに依存するのでおすすめしない。David Kennyによると、These measures are affected by sample size and can be large for models that are poorly specified. The current consensus is not to use these measures.らしい。
- RMSEA: Root Mean Square Error of Approximation。 0.05以下だとよい。信頼区間の計算を薦める。sqrt([([&chi2/df] - 1)/(N - 1)])
- NFI: Normed Fit Index。ヌルモデルとの差。大きいほど、0.95以上だとよい。[&chi2/df(Null Model) - &chi2/df(Proposed Model)]/[&chi2/df(Null Model) - 1]
- TFI: Tucker-Lewis Index。NFIを自由度で補正。大きいほどよい。1を超えることもある
- CFI: Comparative Fit Index。NFIを自由度で補正 (TFIとは違うやりかた) 。大きいほどよい。0.95以上だとよい。[d(Null Model) - d(Proposed Model)]/d(Null Model)
- AIC: Akaike Information Criterion。カイ二乗値に自由度、パラメータ数の補正を加えたもの。小さいほうがよい。相対基準なので、いくつ以下、というのはない。 chi2 + k(k - 1) - 2df
- CAIC: Consistent Akaike Information Criterion。AICのサンプルサイズの補正をさらに加えた。X2+(1+log(N))*(((k*(k-1)-2*df))/2)。Nはサンプルサイズ。
- BIC: Bayesian Information Criterion。事後の分布との比較。小さいほどよい。chi2 + [k(k - 1)/2 - df]ln(N)
- 参考リンク
sem パッケージで確認的因子分析
- 小塩先生の授業ページの例を参考にする。感謝。
- データは15個の観測変数がある (p01...p15) 。なお、元データは小塩先生のサイトから。.datの拡張子をつけているがタブ区切りテキスト。
- 神経症傾向、外向性、開放性、調和性、勤勉性の5つの潜在変数があると想定する。それぞれ変数名をne, ex, op, ag, csとする。
- neはp01, p02, p03に、exはp04, p05, p06…と図のように負荷すると想定する。また、各潜在変数は互いに相関すると仮定し、これを両方向の矢印 (e.g., neex) であらわす。
- e01 - e15は残差分散とする。
- sem関数ではデータとして観測変数の共分散行列か相関行列を与える。
- 確認的因子分析のモデルはspecify.model() 関数を使う。
- この関数では矢印 (->) 、パラメータ名 (パス名) 、初期値の3つを指定する。
- 初期値にNA を指定するとプログラムが初期値を選択する。
- 潜在変数 (ne, ex, ...) の分散が1に固定してある (確認的因子分析の仮定) 。
- 最後に1行空けて終了。
# データ、参考は上述のとおり小塩先生のサイトから。感謝。
dat <- read.delim("http://eau.uijin.com/advstats/images/data_big5.dat")
mat <- cor(dat[3:17])
library(sem)
model <- specify.model()
ne -> p01, b11, 1
ne -> p02, b12, NA
ne -> p03, b13, NA
ex -> p04, b21, NA
ex -> p05, b22, NA
ex -> p06, b23, NA
op -> p07, b31, NA
op -> p08, b32, NA
op -> p09, b33, NA
ag -> p10, b41, NA
ag -> p11, b42, NA
ag -> p12, b43, NA
cs -> p13, b51, NA
cs -> p14, b52, NA
cs -> p15, b53, NA
ne <-> ne, NA, 1
ex <-> ex, NA, 1
op <-> op, NA, 1
ag <-> ag, NA, 1
cs <-> cs, NA, 1
p01 <-> p01, e01, NA
p02 <-> p02, e02, NA
p03 <-> p03, e03, NA
p04 <-> p04, e04, NA
p05 <-> p05, e05, NA
p06 <-> p06, e06, NA
p07 <-> p07, e07, NA
p08 <-> p08, e08, NA
p09 <-> p09, e09, NA
p10 <-> p10, e10, NA
p11 <-> p11, e11, NA
p12 <-> p12, e12, NA
p13 <-> p13, e13, NA
p14 <-> p14, e14, NA
p15 <-> p15, e15, NA
ne <-> ex, neex, NA
ne <-> op, neop, NA
ne <-> ag, neag, NA
ne <-> cs, necs, NA
ex <-> op, exop, NA
ex <-> ag, exag, NA
ex <-> cs, excs, NA
op <-> ag, opag, NA
op <-> cs, opcs, NA
ag <-> cs, agcs, NA
semres <- sem(model, mat, N=250)
(sumsem <- summary(semres)) # Amosの結果と一致
std.coef(semres)
source("http://file.scratchhit.pazru.com/sem.aic2.r")
## こちらで紹介されていたAIC, CAICを求める関数だが、どうもAMOSやLISRELの結果と食い違うようなので修正した。
sem.aic2(semres)
rsquare.sem(semres) # R二乗
sumsem$chisq - sumsem$df * log(semres$N) # BIC
boot.sem( ) 関数で構造方程式モデルをブートストラップでシミュレーションできる。help(boot.sem) 参照。mod.indices() 関数はモデル修正の指標を生成できる。探索的因子分析でも使える。ページ下部の参考リンクをみよう。
lavaan パッケージで確認的因子分析
上と同じ分析をlavaanパッケージでやってみる。lavaanパッケージにもsemという関数があるので、detach(package:sem) でsemパッケージを除去したほうがいいかもしれない。
qgraphパッケージでパス図を書ける。lavaan以外にもいろいろ対応 ("sem" (sem), "mod" (sem), "lavaan" (lavaan), "principal" (psych), "loadings" (stats), "factanal" (stats), "graphNEL" (Rgraphviz) or "pcAlgo" (pcalg)) 。しかし見やすくはない。きれいなパス図を書くにはこちら
# lavaanで分析
dat <- read.delim("http://eau.uijin.com/advstats/images/data_big5.dat")
library(lavaan)
model.lavaan <- '
ne =~ p01 + p02 + p03
ex =~ p04 + p05 + p06
op =~ p07 + p08 + p09
ag =~ p10 + p11 + p12
cs =~ p13 + p14 + p15
'
lavres <- cfa(model.lavaan, data=dat, std.lv=T, mimic="EQS")
summary(lavres, fit.measures=T, standardize = TRUE)
# mimic="EQS"とすると上記のsemやAMOSの結果と一致する。
library(qgraph)
qgraph(lavres) # デフォルトのqgraph
lavaanパッケージ・共分散行列で確認的因子分析
# 心理統計学の基礎, p347-350のもの。感謝
# 表10-1 p318 相関行列
mat <- matrix(c(
1.000,0.033,0.315,0.456,0.266,0.607,0.228,0.419,
0.033,1.000,0.637,0.250,0.528,0.195,0.522,0.420,
0.315,0.637,1.000,0.333,0.880,0.237,0.750,0.328,
0.456,0.250,0.333,1.000,0.362,0.432,0.398,0.449,
0.266,0.528,0.880,0.362,1.000,0.252,0.738,0.269,
0.607,0.195,0.237,0.432,0.252,1.000,0.335,0.463,
0.228,0.522,0.750,0.398,0.738,0.335,1.000,0.238,
0.419,0.420,0.328,0.449,0.269,0.463,0.238,1.000),
nrow=8, dimnames=list(c("onw", "yok", "gai", "sin", "sha", "kyo",
"sek", "sun"), c("onw", "yok", "gai", "sin", "sha", "kyo", "sek",
"sun"))
)
library(lavaan)
model.lavaan <- '
f1 =~ yok+gai+sha+sek
f2 =~ onw+sin+kyo+sun
'
lavres <- cfa(model.lavaan, sample.cov=mat, sample.nobs=200, std.lv=T, mimic="EQS")
summary(lavres, fit.measures=T, standardize = TRUE)
# データが相関行列っぽいけどサポートしてないから違うかもよ、という警告。結果は"ほぼ"同じ。カイ二乗値が微妙に違う
# qgraphパッケージでプロット。見やすくはない
library(qgraph)
qgraph.lavaan(lavres,layout="tree", vsize.man=5, vsize.lat=5, filetype="",include=3,curve=-0.4,edge.label.cex=1, titles=F)
# いろんなプロット。layout, includeを変える。
win.graph()
qgraph.lavaan(lavres, layout="circle", edge.labels = TRUE, include = 2, filetype = "", titles=F)
win.graph()
qgraph.lavaan(lavres, layout="spring", edge.labels = TRUE, include = 3, filetype = "", titles=F)
win.graph()
qgraph.lavaan(lavres, layout="tree", edge.labels = TRUE, include = 6, filetype = "", titles=F)
win.graph()
qgraph.lavaan(lavres, layout="tree", edge.labels = TRUE, include = 2, filetype = "", titles=F)
# もうひとつ心理統計学の基礎の例 共分散構造分析 p351-363 の例を実行
# 表10-8 観測変数間の相関係数 p354
mat <- matrix(c(
1.000,0.160,0.302,0.461,0.299,0.152,0.134,0.182,0.251,0.372,0.157,0.203,
0.160,1.000,0.341,0.400,0.404,0.320,0.403,0.374,0.285,0.100,0.291,-0.014,
0.302,0.341,1.000,0.372,0.552,0.476,0.467,0.572,0.316,0.408,0.393,0.369,
0.461,0.400,0.372,1.000,0.302,0.225,0.256,0.255,0.164,0.236,0.229,0.224,
0.299,0.404,0.552,0.302,1.000,0.708,0.623,0.776,0.361,0.294,0.472,0.342,
0.152,0.320,0.476,0.225,0.708,1.000,0.324,0.769,0.295,0.206,0.351,0.202,
0.134,0.403,0.467,0.256,0.623,0.324,1.000,0.724,0.260,0.071,0.204,0.152,
0.182,0.374,0.572,0.255,0.776,0.769,0.724,1.000,0.284,0.142,0.320,0.189,
0.251,0.285,0.316,0.164,0.361,0.295,0.260,0.284,1.000,0.295,0.290,0.418,
0.372,0.100,0.408,0.236,0.294,0.206,0.071,0.142,0.295,1.000,0.468,0.351,
0.157,0.291,0.393,0.229,0.472,0.351,0.204,0.320,0.290,0.468,1.000,0.385,
0.203,-0.014,0.369,0.224,0.342,0.202,0.152,0.189,0.418,0.351,0.385,1.000),
nr=12,
dimnames = list(paste("y", 1:12, sep=""), paste("y", 1:12, sep=""))
)
mat
library(lavaan)
model.lavaan <- '
f1 =~ y1+y2+y3+y4
f2 =~ y5+y6+y7+y8
f3 =~ y9+y10+y11+y12
f2 ~ f1
f3 ~ f1
f2 ~ 0*f3 # f2とf3が直交と仮定
'
lavres <- cfa(model.lavaan, sample.cov=mat, sample.nobs=50, std.lv=T, mimic="EQS")
summary(lavres, fit.measures=T, standardize = TRUE)
# プロット。見やすくはない
library(qgraph)
qgraph.lavaan(lavres,layout="tree", vsize.man=5, vsize.lat=5, filetype="",include=3,curve=-0.4,edge.label.cex=1)
lavaanパッケージでパス解析
# 小塩先生のサイトより。感謝
kou <- c(34,31,30,17,13,18,17,28,23,29,33,25,37,24,33,38,23,20,26,37)
sek <- c(7,6,4,3,2,4,4,4,5,3,7,3,5,6,6,8,5,3,6,3)
man <- c(8,4,3,5,2,5,2,7,5,4,8,2,6,5,7,7,3,2,8,7)
dat <- data.frame(kou, sek, man)
library(lavaan)
model <- '
sek ~ kou
man ~ kou+sek
'
lavres <- cfa(model, data=dat, std.lv=T, mimic="EQS")
summary(lavres, fit.measures=T, standardize = TRUE)
lavaanの参考リンク
- William Revelleの講義ページから、lavaanの基本的なつかい方、lavaanとsemの比較。
- University of North Texasのサイトより、semの分析とlavaanの分析
- 同サイトより、Structural Equation Modeling without one of the commercial modeling software packages -- or, how you can use free software to impress your committee and/or colleagues. 中身はsemとlavaanの比較
- William Revelleがパス図を描画する関数を開発中らしい。R-helpより、その1、その2。現在のpsychパッケージにはlavaan.diagramという関数があるが、エラーになる。更新版は以下から。
source("http://personality-project.org/R/psych/R/lavaan.diagram.R") - とりあえず、大体semと同じような結果になるのはわかった。semはAmosふうでlavaanはLISREL, M-plusふうといわれてることもわかった。しかしオプションなどまだまだ勉強しないといかんな、と。
構造方程式モデル、semの参考リンク
- 南風原朝和 (2002). 心理統計学の基礎――統合的理解のために―― 有斐閣
- 足立浩平 (2006). 多変量データ解析法――心理・教育・社会系のための入門―― ナカニシヤ出版
- 豊田秀樹・前田忠彦・柳井晴夫 (1992). 原因をさぐる統計学――共分散構造分析入門―― 講談社ブルーバックス
- 千野先生の授業ページ (RAM specificationとは) 、大本
- William Revelleのシラバス **
- Rjpwiki: Rで共分散構造分析・構造方程式モデル
- 神谷先生: 共分散構造分析
- Personality Project: Structural Equation Modeling in R
- Barrett, P. (2007). Structural equation modelling: Adjudging model fit. Personality and Individual Differences, 42, 815-824.
- Friendly, M. (2008). Exploratory and confirmatory factor analysis.
- Fox, J. (2002). Structural Equation Modeling. Appendix to An R and S-PLUS Companion to Applied Regression.
- Fox, J. (2006). Structural Equation Modeling with the sem package in R. Structural Equation Modeling, 13, 465-486.
- Fox, J. (2008). An introduction to structural equation modeling.
- Fox, J. (2009). sem: Structural Equation Models. R package version 0.9-15.
- Loehlin, J. C. (2004) Latent Variable Models (4th ed). Lawrence Erlbaum Associates, Mahwah, N.J.
- Muenchen, R. A. (2009). R for SAS and SPSS Users. Springer.
- Rakov, T. & Marcoulides, G.A. (2006), A first course in structural equation modeling, 2nd Edition; Mawwah,N.J; Erlebaum
- Revelle, W. (2010). psych: Procedures for personality and psychological research. Northwestern University, Evanston, 1.0-92 edition. R package version 1.0-92.
- Revelle, W. (2010). Using the psych package to generate and test structural models.
- Rosseel, Y. (2010). lavaan: Latent Variable Analysis. R package version 0.4-3.
- Bollen, K.A. (2002) Latent variables in psychology and the social sciences. Annual Review of Psychology, 53, 605-634.
足立 (2006) の例をlavaanで実行
# 第6章 パス解析 (その1) p55
# データ入力 表6.1 成績データ
kyo <- c(4, 7, 4, 4, 4, 4, 3, 3, 2, 6, 6, 2, 4, 6, 3, 5, 3, 2, 3, 5, 5, 1, 7, 4, 1, 5, 5, 5, 5, 5, 3, 3, 3, 3, 6, 3, 5, 4, 2, 5, 5, 3, 6, 5, 5, 3, 4, 2, 4, 2, 4, 4, 3, 5, 4, 4, 5, 5, 5, 4)
chi <- c(54, 68, 66, 68, 68, 66, 76, 66, 58, 70, 98, 48, 70, 76, 50, 62, 52, 74, 52, 70, 80, 56, 74, 60, 64, 60, 50, 66, 76, 62, 64, 62, 72, 74, 68, 64, 70, 58, 56, 64, 66, 52, 66, 62, 82, 60, 58, 56, 58, 40, 50, 64, 44, 70, 50, 66, 62, 74, 64, 52)
kes <- c(13.8, 0, 19.6, 17.5, 35.1, 24, 26.1, 32.2, 41.2, 1.115, 10.6, 48, 11.9, 13.7, 39.7, 11.8, 25.2, 34, 33.1, 13, 9.5, 39.7, 11.5, 15.5, 53.6, 23.4, 16.7, 13.9, 26.2, 10.4, 25.5, 27.4, 37, 22.8, 24.2, 35.8, 16.8, 17.5, 25.2, 9.4, 6.2, 38, 5.8, 19.4, 9.9, 36.4, 24, 32.1, 38.8, 30.7, 31.9, 10.5, 19.8, 9.4, 24.5, 25.6, 26, 15.8, 4.8, 43.3)
ben <- c(120, 150, 90, 90, 60, 90, 30, 60, 0, 150, 60, 60, 150, 120, 90, 120, 60, 0, 90, 150, 150, 0, 180, 90, 0, 150, 180, 90, 120, 120, 60, 60, 30, 90, 180, 60, 90, 90, 0, 120, 120, 30, 150, 90, 30, 60, 120, 60, 60, 90, 90, 120, 60, 150, 120, 120, 120, 60, 90, 90)
sei <- c(82, 96, 82, 80, 70, 58, 82, 66, 40, 90, 90, 44, 98, 90, 70, 96, 60, 54, 64, 86, 88, 48, 84, 80, 52, 80, 74, 74, 80, 88, 78, 68, 64, 90, 94, 76, 94, 90, 58, 90, 86, 48, 86, 86, 92, 62, 82, 60, 56, 64, 72, 78, 66, 82, 74, 76, 86, 90, 94, 58)
dat <- data.frame(kyo, chi, kes, ben, sei)
library(psych)
describe(dat)
# 標本分散
sapply(dat, function(a) var(a)*(59/60))
library(lavaan)
model <- '
sei ~ kes+ben+chi
kes ~ kyo
ben ~ kyo+chi
kyo ~~ chi
'
lavres <- cfa(model, data=dat, std.lv=T, mimic="EQS")
summary(lavres, fit.measures=T, standardize = TRUE)
library(qgraph)
qgraph.lavaan(lavres, layout="circle", edge.labels = TRUE, include = 2, filetype = "", titles=F)
# 第8章 確認的因子分析 (その1) p75
# データ入力 表8.1 性格データ
dat <- read.delim("http://eau.uijin.com/advstats/images/data_Adach2006.8-1.dat")
# 要約統計量
mean(dat)
sapply(dat, usd)
sapply(dat, variance)
library(lavaan)
model <- '
f1.katu =~ se+sa+ya+ch
f2.shak =~ yo+bu+ha+ni
'
lavres <- cfa(model, data=dat, std.lv=T, mimic="EQS")
summary(lavres, fit.measures=T, standardize = TRUE)
library(qgraph)
qgraph(lavres)