ˆê”ت‰»گüŒ`ƒ‚ƒfƒ‹
ˆê”ت‰»گüŒ`ƒ‚ƒfƒ‹‚ج‰ًگح‚حglm( ) ‚ة‚و‚èچs‚¤پBڈ‘ژ®‚حˆب‰؛‚ج‚ئ‚¨‚èپB
glm(formula, family=familytype(link=linkfunction), data=)
| Family | Default Link Function |
| binomialپF“ٌچ€•ھ•z | (link = "logit") |
| gaussianپFگ³‹K•ھ•z | (link = "identity") |
| GammaپFƒKƒ“ƒ}•ھ•z | (link = "inverse") |
| inverse.gaussianپF‹tگ³‹K•ھ•z | (link = "1/mu^2") |
| poissonپFƒ|ƒAƒ\ƒ“•ھ•z | (link = "log") |
| quasiپF‹[ژ—–ق“x | (link = "identity", variance = "constant") |
| quasibinomialپF‹[ژ—“ٌچ€•ھ•z | (link = "logit") |
| quasipoissonپF‹[ژ—ƒ|ƒAƒ\ƒ“•ھ•z | (link = "log") |
ƒIƒvƒVƒ‡ƒ“‚ة‚آ‚¢‚ؤڈع‚µ‚‚ح help(glm) ‚â help(family) ‚ًŒ©‚و‚¤پB
‚±‚±‚إ‚حˆê”تگüŒ`ƒ‚ƒfƒ‹‚ج‚¤‚؟ƒچƒWƒXƒeƒBƒbƒN‰ٌ‹AپAƒ|ƒAƒ\ƒ“‰ٌ‹AپAگ¶‘¶ژٹش•ھگح‚ة‚آ‚¢‚ؤڈذ‰î‚·‚éپB.
ƒچƒWƒXƒeƒBƒbƒN‰ٌ‹A
ƒچƒWƒXƒeƒBƒbƒN‰ٌ‹A‚حکA‘±—ت‚إ‚ ‚é—\‘ھ•دگ”‚©‚ç2’l•دگ”‚ً—\‘ھ‚·‚é‚ئ‚«‚ة—p‚¢‚éپBگ§–ٌ‚ھڈ‚ب‚¢‚ج‚إ”»•ت•ھگح‚و‚è‚àچD‚ـ‚ê‚éپB—\‘ھ•دگ”‚ةƒJƒeƒSƒٹƒJƒ‹•دگ”‚ًٹـ‚ك‚邱‚ئ‚à‚إ‚«‚éپB
# ƒfپ[ƒ^‚ئspssŒ‹‰ت‚حucla‚جƒTƒCƒg‚©‚çپBٹ´ژسپB
# ˆب‰؛‚àژQچl: R Data Analysis Examples Logit Regression
# ƒfپ[ƒ^ڈ€”ُ
library(foreign)
dat <- read.spss("http://www.ats.ucla.edu/stat/data/hsb2.sav", to.data.frame=T)
names(dat) <- tolower(names(dat))
honcomp <- as.integer(dat$write>=60)
ses2 <- factor(dat$ses, levels=c("high", "middle", "low")) # ƒٹƒtƒ@ƒŒƒ“ƒXƒJƒeƒSƒٹ‚ً•د‚¦‚é
dat2 <- data.frame(dat, honcomp, ses2)
fit <- glm(honcomp~read+science+ses2, data=dat2, family=binomial("logit")) # ses2‚حƒJƒeƒSƒٹƒJƒ‹•دگ”
# ŒWگ” (B) پAŒWگ”‚ج•Wڈ€Œëچ· (S.E.) پA—Lˆسگ« (Sig.) پB () ‚حSPSS‚إ‚ج•\ژ¦پB
summary(fit)
# گM—ٹ‹وٹش
confint(fit)
# ‰ٌ‹AŒWگ”‚جژwگ”پBƒIƒbƒY”ن (Exp(B))
exp(coef(fit))
# ƒIƒbƒY”ن‚جگM—ٹ‹وٹش
exp(confint(fit))
# —\‘ھ’l
predict(fit, type="response")
# –ق—£“x
residuals(fit, type="deviance")
# Wald“Œv—ت
library(aod)
# read‚جwaldŒں’è
wald.test(b=coef(fit), Sigma=vcov(fit), Terms=2)
# science‚جwaldŒں’è
wald.test(b=coef(fit), Sigma=vcov(fit), Terms=3)
# Nagelkerke R2 (’†àVگوگ¶‚جƒTƒCƒg‚و‚èپBٹ´ژسپB)
NagelkerkeR2 <- function(rr,n) {(1-exp((rr$dev-rr$null)/n))/(1-exp(-rr$null/n)) }
print(NagelkerkeR2(fit,nrow(dat)))
# ‘خگ”–ق“x
logLik(fit) # summary()‚جResidual deviance
-2*logLik(fit)
# ƒvƒچƒbƒg
x1 <- fit$linear.predictor # —\‘ھ•دگ”
y <- dat2$honcomp # –ع“I•دگ”
x2 <- seq(from=min(x1), to=max(x1), length=200) # ‹بگü•`‰و—p
y2 <- exp(x2)/(1+exp(x2)) # ‹بگü•`‰و—p
par(mfrow=c(2,1))
plot(x1, y, pch = ifelse(y=="1", 16, 1))
lines(x2, y2)
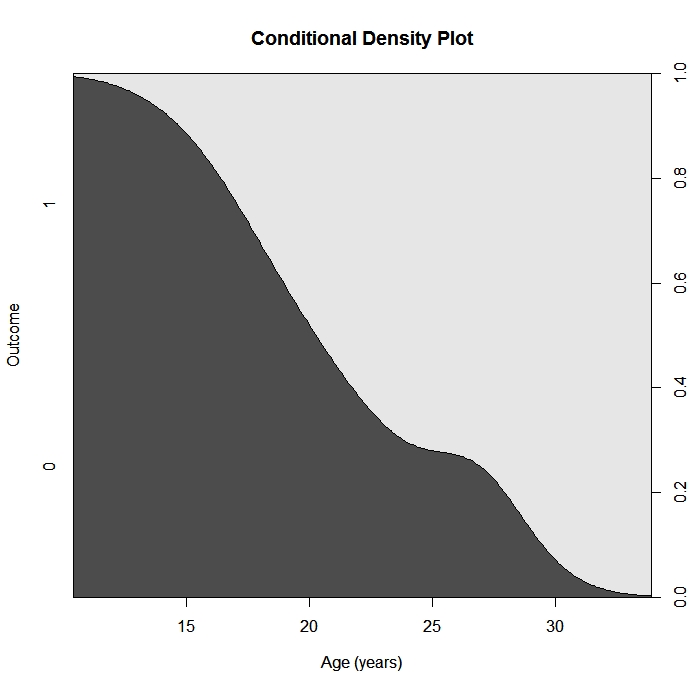
cdplot(factor(y)~x1)
anova(fit1,fit2, test="Chisq") ‚ئ‚·‚é‚ئƒ‚ƒfƒ‹‚ج“Kچ‡“x‚ً”نٹr‚إ‚«‚éپB
cdplot(F~x, data=mydata) ‚حپA2’l•دگ”F‚ًکA‘±•د—تx‚إ—\‘ھ‚µ‚½‚ئ‚«‚جڈًŒڈ‚آ‚«‚ج–§“xƒvƒچƒbƒg‚ً•\ژ¦‚إ‚«‚éپB
 click to view
click to view
ƒ|ƒAƒ\ƒ“‰ٌ‹A
کA‘±•د—ت‚©‚çŒvگ”ƒfپ[ƒ^‚ً—\‘ھ‚·‚é‚ئ‚«‚ة—p‚¢‚éپB
# —ل‚ة‚و‚ء‚ؤUCLA‚جƒTƒCƒg‚©‚çپBٹ´ژسپBŒ‹‰ت‚حSPSS‚ةˆê’vپB
# ƒfپ[ƒ^ڈ€”ُ
library(foreign)
dat <- read.spss("http://www.ats.ucla.edu/stat/spss/dae/poisson_sim.sav", to.data.frame=T)
prog2 <- factor(dat$prog, levels=c("vocation", "academic", "general"))
dat2 <- data.frame(dat, prog2)
# ‹Lڈq“Œv
library(psych)
describe.by(dat$num_awards, list(dat2$prog2))
fit <- glm(num_awards~prog2+math, data=dat2, family=poisson())
summary(fit)
# ŒWگ”‚جگM—ٹ‹وٹشپAƒIƒbƒY”نپAƒIƒbƒY”ن‚جگM—ٹ‹وٹش
confint(fit)
exp(coef(fit))
exp(confint(fit))
‰ك•ھژU (overdispersion) ‚ھگ¶‚¶‚½‚ئ‚«پA‚·‚ب‚ي‚؟ژcچ·–ق—£“x‚ھژ©—R“x‚ً’´‚¦‚é‚و‚¤‚بڈêچ‡‚حپAŒëچ·•ھ•z‚ةquasipoisson() ‚ًژg—p‚·‚éپB
گ¶‘¶ژٹش•ھگح
گ¶‘¶ژٹش•ھگح (survival analysis, event history analysis or reliability analysis‚ئ‚à‚¢‚¤) ‚حƒCƒxƒ“ƒg (e.g., ژ€–SپAŒجڈل) ‚ئ‚»‚±‚ـ‚إ‚جژٹشپA‚·‚ب‚ي‚؟گ¶‘¶ژٹش‚ئ‚ظ‚©‚ج•دگ”‚ئ‚جٹضŒW‚ًƒ‚ƒfƒٹƒ“ƒO‚·‚邱‚ئ‚إ‚ ‚éپBƒfپ[ƒ^‚حŒ¤‹†ڈI—¹‚ـ‚إƒCƒxƒ“ƒg‚ھ‹N‚«‚ب‚¢ right censored ‚إ‚ ‚ء‚½‚èپAƒCƒxƒ“ƒg‚ح‹N‚«‚ؤ‚¢‚ب‚¢‚ھژQ‰ءژز‚ھƒhƒچƒbƒvƒAƒEƒg‚µ‚½‚و‚¤‚ب•sٹ®‘Sڈî•ٌ‚إ‚ ‚ء‚½‚è‚·‚邱‚ئ‚à‚ ‚éپB
گ¶‘¶ژٹش•ھگح‚ة‚حglmٹضگ”‚إ‚ح‚ب‚ survival ƒpƒbƒPپ[ƒW‚جٹضگ”‚ًژg‚¤پBsurvival ƒpƒbƒPپ[ƒW‚حone and two sample problems, parametric accelerated failure model‚âƒRƒbƒNƒX”ن—لƒnƒUپ[ƒhƒ‚ƒfƒ‹‚ًˆµ‚¦‚éپB
ƒfپ[ƒ^‚ة‚حstart time, stop time, and status (1=ƒCƒxƒ“ƒg”گ¶, 0=ƒCƒxƒ“ƒg‚ب‚µ) ‚جڈî•ٌ‚ھ‚ ‚éپB‚ ‚é‚¢‚حƒCƒxƒ“ƒg‚ـ‚إ‚جژٹش (time to event) ‚ئ status ‚ئ‚¢‚¤ڈêچ‡‚à‚ ‚éپBstatus=0‚ئ‚حگوڈq‚جright cencored‚ًˆس–،‚·‚éپBƒfپ[ƒ^‚ح‚ـ‚¸Survٹضگ”‚ً‚à‚؟‚¢‚ؤSurvƒIƒuƒWƒFƒNƒg‚ة‚µ‚ؤ‚¨‚•K—v‚ھ‚ ‚éپB
survfit( ) ٹضگ”‚إ‚ذ‚ئ‚آ‚ـ‚½‚ح•،گ”‚جŒQ‚جگ¶‘¶•ھ•z‚ًگ„’è‚إ‚«‚éپB
survdiff( ) ٹضگ”‚ة‚و‚è2‚آˆبڈم‚جŒQ‚جگ¶‘¶•ھ•z‚جچ·‚ًŒں’è‚إ‚«‚éپB
coxph( ) ٹضگ”‚إ—\‘ھ•دگ”‚ة‘خ‚·‚éƒnƒUپ[ƒhٹضگ”‚ج‚ ‚ؤ‚ح‚ـ‚è‚ًƒ‚ƒfƒٹƒ“ƒO‚إ‚«‚éپB
ˆب‰؛ژQچl
- Applied Longitudinal Data Analysis: Modeling Change and Event Occurrence
- Applied Survival Analysis: Regression Modeling of Time to Event Data
- Computer-Aided Multivariate Analysis, 4th Edition
- گ¶‘¶ژٹش‰ًگح“ü–ه
- ‚q‚ئگ¶‘¶ژٹش•ھگح(1)
- ‚q‚ئگ¶‘¶ژٹش•ھگح(2)
# Mayo Clinic Lung Cancer Data
library(survival)
# ƒfپ[ƒ^ƒZƒbƒg‚ة‚آ‚¢‚ؤ
help(lung)
# Surv ƒIƒuƒWƒFƒNƒg‚جگ¶گ¬
survobj <- with(lung, Surv(time,status))
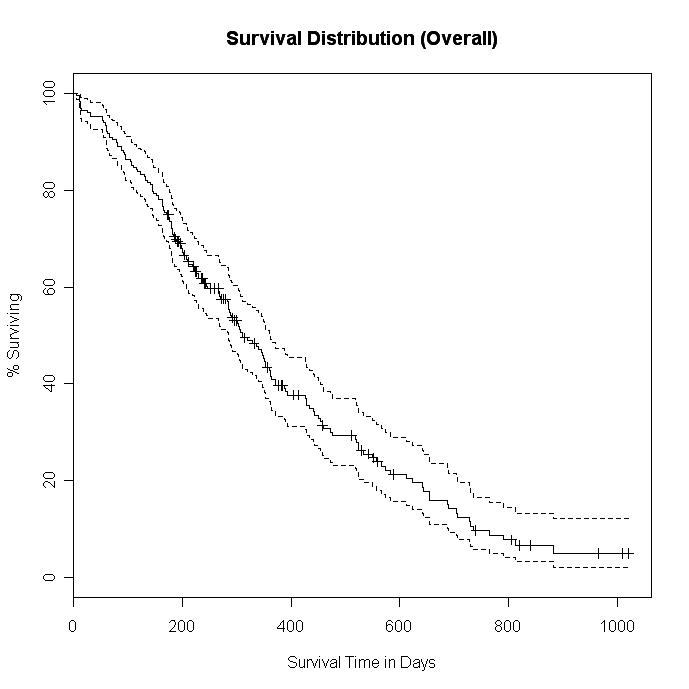
# ‘SƒTƒ“ƒvƒ‹‚جگ¶‘¶•ھ•z‚ًƒvƒچƒbƒg
# Kaplan-Meier گ„’è
fit0 <- survfit(survobj~1, data=lung)
summary(fit0)
plot(fit0, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100,
main="Survival Distribution (Overall)")
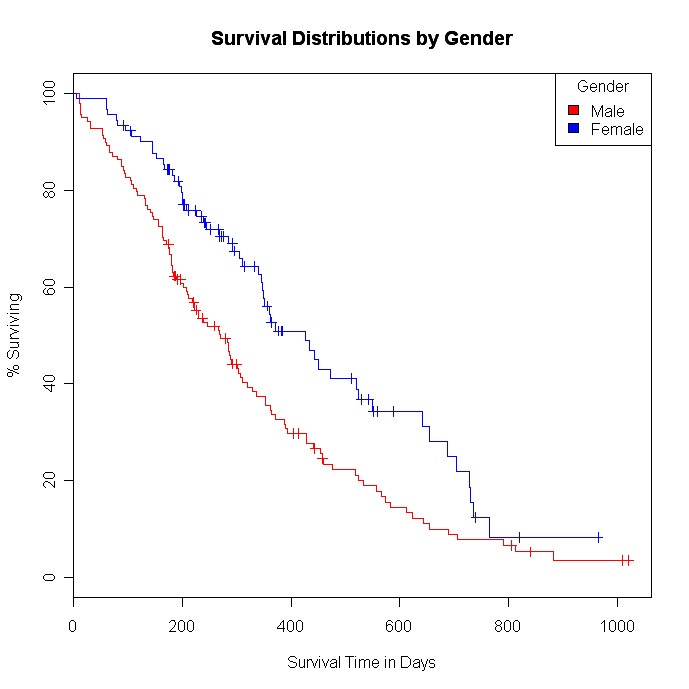
# گ«•ت‚إگ¶‘¶•ھ•z‚ً”نٹr
fit1 <- survfit(survobj~sex,data=lung)
# گ«•ت‚²‚ئ‚ةƒvƒچƒbƒg
plot(fit1, xlab="Survival Time in Days",
ylab="% Surviving", yscale=100, col=c("red","blue"),
main="Survival Distributions by Gender")
legend("topright", title="Gender", c("Male", "Female"),
fill=c("red", "blue"))
# گ«چ·‚جŒں’è
# گ¶‘¶‹بگü (ƒچƒOƒ‰ƒ“ƒNŒں’è)
survdiff(survobj~sex, data=lung)
# ”N—î‚ئˆم—أ“¾“_‚©‚ç’jگ«‚جگ¶‘¶‚ً—\‘ھ
MaleMod <- coxph(survobj~age+ph.ecog+ph.karno+pat.karno,
data=lung, subset=sex==1)
# Œ‹‰ت‚ج•\ژ¦
MaleMod
# ”ن—لƒnƒUپ[ƒh‰¼’è‚ج•]‰؟
cox.zph(MaleMod)
 click to view
click to view
Thomas Lumley's R news‚ج‹Lژ–پAMai Zhou ‚جUse R Software to do Survival Analysis and Simulation پAM. J. Crawley‚جSurvival Analysis ‚àژQڈئپB
ƒ}ƒ‹ƒ`ƒŒƒxƒ‹ƒ‚ƒfƒ‹
گüŒ`چ¬چ‡ƒ‚ƒfƒ‹پAˆê”ت‰»گüŒ`چ¬چ‡ƒ‚ƒfƒ‹‚ئ‚©‚¢‚ء‚½‚è‚·‚éپB
Kreft, I., & de Leeuw, J. (1998). Introducing multilevel modeling. Newbury Park, CA: Sage. (ƒNƒŒƒtƒg, I., ƒfƒŒƒE, J. ڈ¬–ىژ›چF‹` (•ز–َ) (2006). ٹî‘b‚©‚çٹw‚شƒ}ƒ‹ƒ`ƒŒƒxƒ‹ƒ‚ƒfƒ‹پ\“ü‚è‘g‚ٌ‚¾•¶–¬‚©‚çگV‚½‚ب—ک_‚ً‘nڈo‚·‚邽‚ك‚ج“Œvژè–@پ@ƒiƒJƒjƒVƒ„ڈo”إ
‚ًR‚إژہچsپB
ˆب‰؛ژQچl
- R‚ة‚و‚éƒ}ƒ‹ƒ`ƒŒƒxƒ‹ƒ‚ƒfƒٹƒ“ƒO‚ج—ûڈK
- Textbook Examples Introduction to Multilevel Modeling by Kreft and de Leeuw
- Lesa Hoffman's Home Page
- Hoffman, L., & Rovine, M.J. (2007). Multilevel models for the experimental psychologist: Foundations and illustrative examples. Behavior Research Methods, 39(1), 101-117.
- Nezlek, J. B. (2008). An Introduction to multilevel modeling for social and personality psychology. Social and Personality Psychology Compass, 2, 842-860.
‘و2ڈح
## •\2.1 ٹwچZ“à•½‹د p21
size <- as.vector(table(dat[1]))
dat.agmean <- aggregate(dat[c(3,4)], list(dat[,1]), mean)
tbl2.1 <- data.frame(school=1:10, size, dat.agmean[2:3])
tbl2.1
## •\2.2 ژU•z“x ‹¤•ھژUچs—ٌ‚ئ‘ٹٹضŒWگ” p21
by(dat[3:4], dat[1], function(x) cov(x)*((nrow(x)-1)/nrow(x)))
by(dat[3:4], dat[1], cor)
## •\2.3 10چZ‚ج‘S‘ج‰ٌ‹A p24
summary(lm(math~1, dat))
summary(lm(math~homework, dat))
## •\2.4 10چZ‚جڈWŒv‰ٌ‹A p24
summary(lm(math~1, dat.agmean, weights=size))
summary(lm(math~homework, dat.agmean, weights=size))
## •\2.5 10چZ‚ة‘خ‚·‚镶–¬ƒ‚ƒfƒ‹ p25
dat$schid <- factor(dat$schid)
cx <- rep(dat.agmean[,3], size)
dat$cx <- cx
summary(lm(math~1, dat))
summary(lm(math~homework+cx, dat))
## •\2.6 10چZ‚جƒNƒچƒ“ƒoƒbƒNƒ‚ƒfƒ‹ p26
dat$bw <- dat$homework-dat$cx
dat$bb <- dat$cx - mean(dat$homework)
summary(lm(math~1, dat))
summary(lm(math~bw+bb, dat))
## •\2.7 10چZ‚جANCOVAƒ‚ƒfƒ‹ p28 # گ„’è’l‚ةٹض‚µ‚ؤ‚ح‹³‰بڈ‘‚ا‚¨‚è‚جŒ‹‰ت‚ة‚ب‚ç‚ب‚¢‚ھپAٹî–{“I‚ةگط•ذ‚©‚ç‚جچ·•ھ‚ھ‰ٌ‹AŒWگ”‚ئ‚³‚ê‚ؤ‚¢‚é‚ج‚إ–â‘è‚ب‚µپA‚ئ‚¢‚¤‚±‚ئ‚ة‚µ‚و‚¤ (predict(ƒIƒuƒWƒFƒNƒg) ‚إ‚à‚¢‚¢) پBŒˆ’èŒWگ”‚ئ‚©‚ح“¯‚¶
lmres.null <- lm(math~schid, dat)
lmres.acv <- lm(math~schid+homework, dat)
summary(lmres.null)
summary(lmres.acv)
‘و3ڈح
library(foreign)
dat0 <- data.frame(read.spss("http://www.ats.ucla.edu/stat/spss/examples/mlm_imm/imm10.sav"))
names(dat0) <- tolower(names(dat0))
data.frame(names(dat0))
dat <- dat0[c(1,2,11,5,8,19)]
head(dat)
dat.agmean <- aggregate(dat[3:5], list(dat[,1]), mean)
dat.agmean
# ŒX‚«‚ًŒ‹‰ت•دگ”‚ئ‚·‚éƒAƒvƒچپ[ƒ`
## •\3.2پ@10چZ‚جڈh‘è‚ة‘خ‚·‚éگ”ٹw‚جگ¬گر‚جOLS‰ٌ‹Aپ@p41
by(dat[3:4], dat[1], cor) # ‘ٹٹضŒWگ”
by(dat, dat$schid, function(x) coef(summary(lm(math~homework, x)))) # ٹwچZ‚²‚ئ‚ةƒfپ[ƒ^‚ً•ھٹ„‚µپAmath~homework‚ج‰ٌ‹A•ھگح‚ًچs‚ء‚½‚à‚ج
summary(lm(math~homework, dat)) #p24 •\2.3‚ئ“¯‚¶
## ƒ}ƒNƒچ‰ٌ‹A‚جŒ‹‰ت
bylmres <- by(dat, dat$schid, function(x) lm(math~homework, x))
a <- sapply(bylmres, coef)
intc <- a[1,]
slp <- a[2,]
pbl <- factor(dat.agmean[,4])
summary(lm(intc~pbl))
summary(lm(slp~pbl))
## •\3.3پ@ƒ‰ƒ“ƒ_ƒ€ŒWگ”ƒ‚ƒfƒ‹ p42
# ƒŒƒxƒ‹1 Y=math, X = homework, i=Œآگl, j=ٹwچZ, ƒأ=Œëچ·
## ƒہ0j, ƒہ1j ‚ح‚»‚ꂼ‚êaj, bj‚ئ‚à•\‹L‚³‚ê‚é (‹³‰بڈ‘’†) پBٹwچZ‚جگط•ذ‚و‚رŒX‚«‚ً•\‚·پB
## چإڈ‰‚ج“Y‚¦ژڑ (i) ‚حƒ~ƒNƒچگ…ڈ€پAŒم‚ج“Y‚¦ژڑ‚ح (j) ‚حƒ}ƒNƒچگ…ڈ€‚ًژ¦‚·پB‚آ‚ـ‚èi‚حƒlƒXƒg‚³‚ê‚é•دگ”پAj‚حƒlƒXƒg‚·‚é•دگ”پB‚±‚ج—ل‚إ‚حŒآگl‚ھi, ٹwچZ‚ھjپB‚ـ‚½پA—ل‚¦‚خ“ْ‚²‚ئ‚ج”½•œ‘ھ’è‚ب‚çi‚ھ“ْپAj‚ھŒآگl‚ئ‚ب‚é
## •\3.3پAگ…ڈ€1‚ج•ھژU‚حƒأij‚إ‚ ‚èپAڈd‰ٌ‹A•ھگح‚إ‚¢‚¤‚ئ‚±‚ë‚جŒëچ·چ€‚ة‚ ‚½‚éپBVarCorrٹضگ”‚جResiduals‚ة‚ ‚½‚éپB
# Yij = ƒہ0j + ƒہ1jXij + ƒأij
# ƒŒƒxƒ‹2 # ƒء00=گط•ذ‚ج‘S‘ج‚ج•½‹د, ƒء10=‘S‘ج‚جŒX‚«پAu=Œëچ·
## VarCorrٹضگ”‚إڈo—ح‚³‚ê‚é•ھژUگ¬•ھپA‚¨‚و‚ر‹³‰بڈ‘•\3.3‚جپuگ…ڈ€2پv‚جپuگ„’è’lپv‚ئ‚ح‚±‚±‚جu0j, u1j‚جŒëچ·•ھژU‚ًژ¦‚·پB
# ƒہ0j = ƒء00 + u0j
# ƒہ1j = ƒء10 + u1j
library(nlme)
lme.res <- lme(math ~ homework, random=~homework|schid, data=dat, method="ML")
summary(lme.res)
VarCorr(lme.res)
getVarCov(lme.res) # •ھژU
logLik(lme.res)*-2 # ˆي’E“x
intervals(lme.res) # گM—ٹ‹وٹش
## •\3.4 p44
lme.res2 <- lme(math ~ homework+public, random=~homework|schid, data=dat, method="ML")
summary(lme.res2)
VarCorr(lme.res2)
getVarCov(lme.res2) # •ھژU
logLik(lme.res2)*-2 # ˆي’E“x
intervals(lme.res2) # گM—ٹ‹وٹش
## •\3.5 p45
lme.res3 <- lme(math~homework+public+homework:public, random=~homework|schid, data=dat, method="ML")
summary(lme.res3)
VarCorr(lme.res3)
getVarCov(lme.res3) # •ھژU
logLik(lme.res3)*-2 # ˆي’E“x
intervals(lme.res3) # گM—ٹ‹وٹش
## •\3.6 p46
lme.res4 <- lme(math~homework, random=~homework|schid, data=dat, method="ML")
summary(lme.res4)
VarCorr(lme.res4)
getVarCov(lme.res4) # •ھژU
logLik(lme.res4)*-2 # ˆي’E“x
intervals(lme.res4) # گM—ٹ‹وٹش
cf.v <- coef(lme.res4)
cf.v
## گ}3.8
n<-nrow(cf.v)
x<-cbind(0, 7)
y<-cbind(seq(1:n), seq(1:n))
y[,1]<-cf.v[,1]
y[,2]<-cf.v[,1]+cf.v[,2]*7
plot(x, y[1,], type="l", ylab="predicte", ylim=c(20,100))
for (i in 2:n){points(x, y[i,], type="l", lty=i)}
‘و4ڈح
library(foreign)
dat0 <- data.frame(read.spss("http://www.ats.ucla.edu/stat/spss/examples/mlm_imm/imm23.sav"))
names(dat0) <- tolower(names(dat0))
data.frame(names(dat0))
library(psych)
describe(dat0)
dat.corr <- dat0[c(3,5,6,8)]
corr.test(dat.corr)
## •\4.2پ@ƒkƒ‹ƒ‚ƒfƒ‹پ@p57
library(nlme)
library(multilevel)
model.null <- lme(math~1, random=~1|schid, data=dat0, method="ML")
summary(model.null)
VarCorr(model.null)
getVarCov(model.null) # •ھژU
logLik(model.null)*-2 # ˆي’E“x
intervals(model.null) # گM—ٹ‹وٹش. Randome effect ‚ھگ…ڈ€2پAWithin...‚ھگ…ڈ€1
library(multilevel)
GmeanRel(model.null) # ‹‰“à‘ٹٹضپBpsychometricƒpƒbƒPپ[ƒW‚ة‚àژ—‚½‚و‚¤‚ب‚ج‚ھ‚ ‚é
## •\4.3 p58
model1 <- lme(math~homework, random=~1|schid, data=dat0, method="ML")
summary(model1)
VarCorr(model1)
getVarCov(model1) # •ھژU
logLik(model1)*-2 # ˆي’E“x
intervals(model1) # گM—ٹ‹وٹش
GmeanRel(model1) # ‹‰“à‘ٹٹض
## •\4.4 p59
model2 <- lme(math~homework, random=~homework|schid, data=dat0, method="ML")
summary(model2)
VarCorr(model2)
getVarCov(model2) # •ھژU
logLik(model2)*-2 # ˆي’E“x
intervals(model2) # گM—ٹ‹وٹش
GmeanRel(model2) # ‹‰“à‘ٹٹض
## •\4.5 p61
model3 <- lme(math~homework+parented, random=~homework|schid, data=dat0, method="ML")
summary(model3)
VarCorr(model3)
getVarCov(model3) # •ھژU
logLik(model3)*-2 # ˆي’E“x
intervals(model3) # گM—ٹ‹وٹش
GmeanRel(model3) # ‹‰“à‘ٹٹض
## •\4.6 p62
model4 <- lm(math~homework+parented, data=dat0)
summary(model4)
logLik(model4)*-2 # ˆي’E“x
## •\4.7پ@p65
model2s2 <- lme(math~homework + scsize, random=~homework|schid, data=dat0, method="ML")
summary(model2s2)
VarCorr(model2s2)
getVarCov(model2s2) # •ھژU
logLik(model2s2)*-2 # ˆي’E“x
intervals(model2s2) # گM—ٹ‹وٹش
GmeanRel(model2s2) # ‹‰“à‘ٹٹض
## •\4.8پ@p66
model3s2 <- lme(math~homework + public, random=~homework|schid, data=dat0, method="ML")
summary(model3s2)
VarCorr(model3s2)
getVarCov(model3s2) # •ھژU
logLik(model3s2)*-2 # ˆي’E“x
intervals(model3s2) # گM—ٹ‹وٹش
GmeanRel(model3s2) # ‹‰“à‘ٹٹض
## •\4.9 p67
dat0$hp <- dat0$homework*dat0$public
dat0$hm <- dat0$homework*dat0$meanses
dat0$hr <- dat0$homework*dat0$ratio
cmat <- cor(dat0[,c("public", "meanses", "ratio", "homework", "hp", "hm", "hr")])
cmat[c(5:7,4),]
## •\4.10پ@p68
model4s2 <- lme(math~homework+public+homework:public, random=~homework|schid, data=dat0, method="ML")
summary(model4s2)
VarCorr(model4s2)
getVarCov(model4s2) # •ھژU
logLik(model4s2)*-2 # ˆي’E“x
intervals(model4s2) # گM—ٹ‹وٹش
GmeanRel(model4s2) # ‹‰“à‘ٹٹض
###########
# •\4.11 ƒfپ[ƒ^‚ب‚µ
##########
## •\4.12پ@p72
model5s2 <- lme(math~homework+white+public, random=~homework|schid, data=dat0, method="ML")
summary(model5s2)
VarCorr(model5s2)
getVarCov(model5s2) # •ھژU
logLik(model5s2)*-2 # ˆي’E“x
intervals(model5s2) # گM—ٹ‹وٹش
GmeanRel(model5s2) # ‹‰“à‘ٹٹض
## •\4.13پ@p73
model6s2 <- lme(math~homework + public + white, random=~homework + white|schid, data=dat0, method="ML")
summary(model6s2)
VarCorr(model6s2)
getVarCov(model6s2) # •ھژU
logLik(model6s2)*-2 # ˆي’E“x
intervals(model6s2) # گM—ٹ‹وٹش
GmeanRel(model6s2) # ‹‰“à‘ٹٹض
## •\4.14پ@p74
model7s2 <- lme(math~homework+white+public+meanses, random=~homework|schid, data=dat0, method="ML")
summary(model7s2)
VarCorr(model7s2)
getVarCov(model7s2) # •ھژU
logLik(model7s2)*-2 # ˆي’E“x
intervals(model7s2) # گM—ٹ‹وٹش
GmeanRel(model7s2) # ‹‰“à‘ٹٹض
## •\4.15پ@p75
model8s2 <- lme(math~homework+white+meanses, random=~homework|schid, data=dat0, method="ML")
summary(model8s2)
VarCorr(model8s2)
getVarCov(model8s2) # •ھژU
logLik(model8s2)*-2 # ˆي’E“x
intervals(model8s2) # گM—ٹ‹وٹش
GmeanRel(model8s2) # ‹‰“à‘ٹٹض
## •\4.16پ@p76
model9s2 <- lme(math~homework+white+meanses+homework:meanses, random=~homework|schid, data=dat0, method="ML")
summary(model9s2)
VarCorr(model9s2)
getVarCov(model9s2) # •ھژU
logLik(model9s2)*-2 # ˆي’E“x
intervals(model9s2) # گM—ٹ‹وٹش
GmeanRel(model9s2) # ‹‰“à‘ٹٹض
## •\4.17پ@p77
model10s2 <- lme(math~homework+white+meanses+ses, random=~homework|schid, data=dat0, method="ML")
summary(model10s2)
VarCorr(model10s2)
getVarCov(model10s2) # •ھژU
logLik(model10s2)*-2 # ˆي’E“x
intervals(model10s2) # گM—ٹ‹وٹش
GmeanRel(model10s2) # ‹‰“à‘ٹٹض
## •\4.18پ@ƒfپ[ƒ^‚ب‚µ
## •\4.19پ@p79
model1s3 <- lme(math~ses, random=~1|schid, data=dat0, method="ML")
summary(model1s3)
VarCorr(model1s3)
getVarCov(model1s3) # •ھژU
logLik(model1s3)*-2 # ˆي’E“x
intervals(model1s3) # گM—ٹ‹وٹش
GmeanRel(model1s3) # ‹‰“à‘ٹٹض
## •\4.20پ@p80
model2s3 <- lme(math~ses, random=~ses|schid, data=dat0, method="ML")
summary(model2s3)
VarCorr(model2s3)
getVarCov(model2s3) # •ھژU
logLik(model2s3)*-2 # ˆي’E“x
intervals(model2s3) # گM—ٹ‹وٹش
GmeanRel(model2s3) # ‹‰“à‘ٹٹض
## •\4.21پ@p81
model3s3 <- lme(math~ses+percmin, random=~1|schid, data=dat0, method="ML")
summary(model3s3)
VarCorr(model3s3)
getVarCov(model3s3) # •ھژU
logLik(model3s3)*-2 # ˆي’E“x
intervals(model3s3) # گM—ٹ‹وٹش
GmeanRel(model3s3) # ‹‰“à‘ٹٹض
## •\4.22پ@p82
model4s3 <- lme(math~ses+percmin+meanses, random=~1|schid, data=dat0, method="ML")
summary(model4s3)
VarCorr(model4s3)
getVarCov(model4s3) # •ھژU
logLik(model4s3)*-2 # ˆي’E“x
intervals(model4s3) # گM—ٹ‹وٹش
GmeanRel(model4s3) # ‹‰“à‘ٹٹض
## •\4.25پ@p86
model1s4 <- lme(math~homework+ratio, random=~homework|schid, data=dat0, method="ML")
summary(model1s4)
VarCorr(model1s4)
getVarCov(model1s4) # •ھژU
logLik(model1s4)*-2 # ˆي’E“x
intervals(model1s4) # گM—ٹ‹وٹش
GmeanRel(model1s4) # ‹‰“à‘ٹٹض
## •\4.26پ@p87
model2s4 <- lme(math~homework+homework:ratio, random=~homework|schid, data=dat0, method="ML")
summary(model2s4)
VarCorr(model2s4)
getVarCov(model2s4) # •ھژU
logLik(model2s4)*-2 # ˆي’E“x
intervals(model2s4) # گM—ٹ‹وٹش
GmeanRel(model2s4) # ‹‰“à‘ٹٹض